13/05/2026
ARTICLE


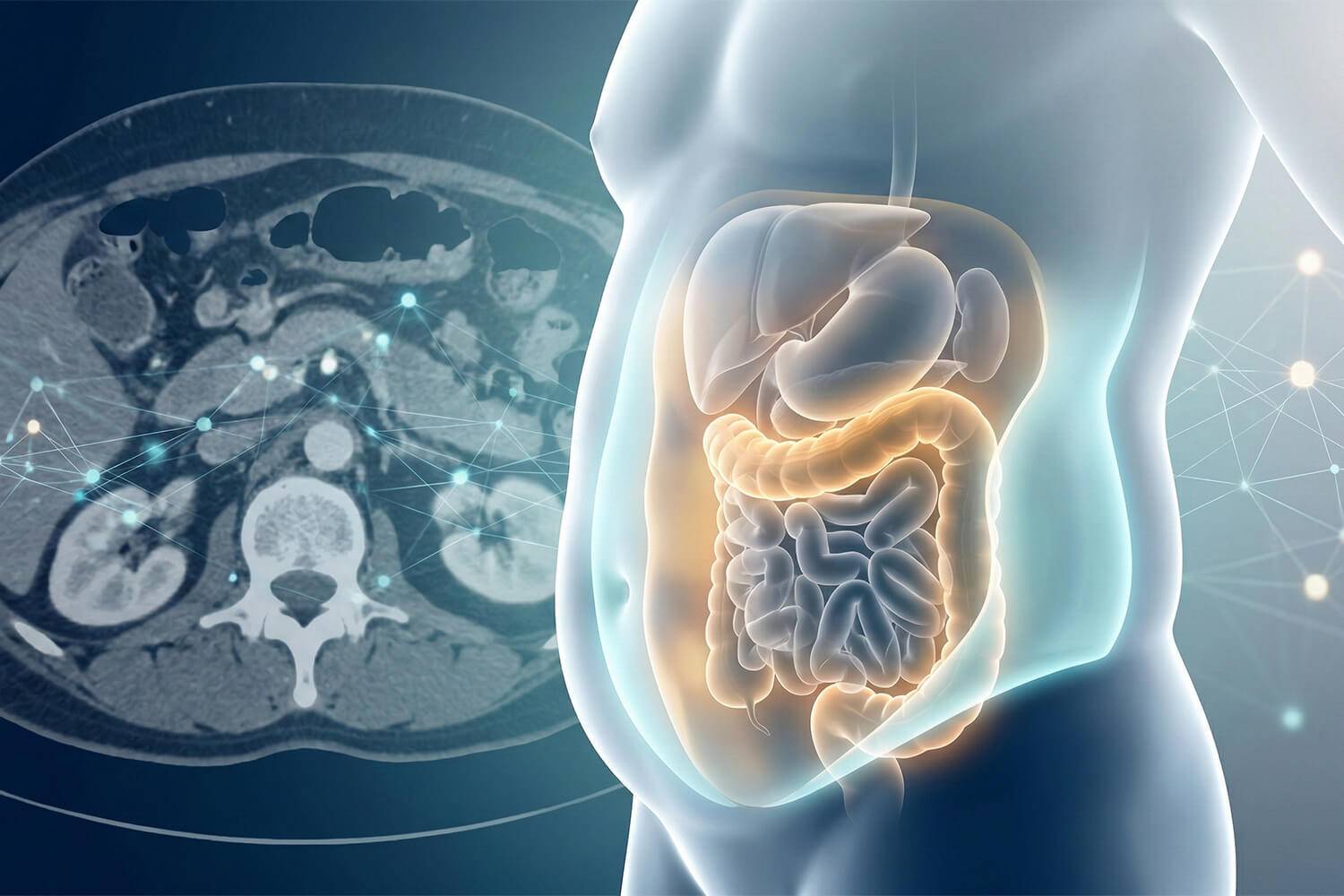
Le ratio entre graisse viscérale et graisse sous-cutanée est un indicateur de risque de diabète de type 2 plus précis que l'indice de masse corporelle (IMC).
Diabète : pourquoi l'IMC ne suffit plus pour évaluer le risque. Une étude montre que le ratio graisse viscérale/graisse sous-cutanée, analysé par IA, prédit bien mieux le diabète de type 2 que le simple calcul du poids. Découvrez comment l'imagerie et l'intelligence artificielle révolutionnent le dépistage de l'obésité métabolique.



©2026 Medipodcast®

Remplissez le formulaire ci-dessous pour créer votre compte